SQL Analytic Functions
Window functions play a very important part in analytic queries. I explore some of the window functions using Postgres 13.4. Window function defaults differ from Postgres to Redshift, although the results are the same. The OVER () default for Redshift is (ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING). Postgres's default is (RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW). When writing this post, Redshift hasn't implemented the RANGE. Therefore, I haven't mixed the two databases and only stuck to Postgres.
This post is created using Jupyter Notebook. I've used Jupyter Magics. For example, the Jupyter SQL Magic result set was converted as Pandas data frame and plotted graph.
Setup Jupyter Notebook and Postgres
If you want to experiment with these queries, you must install Docker containers for Postgres1 and AWS Glue container2 (Jupyter).
Here is the first step to load Jupyter SQL Magic.
%load_ext sql
Then you must use the SQL Magic connection string to connect to the Postgres database, as shown in line #1.
Find the total salary expenditure for each department and the entire organisation.
%%sql postgresql+pg8000://postgres:***@postgres_db:5432/company result <<
select dept_name, sum(salary_amt)
from payroll
group by rollup(dept_name)
order by dept_name
4 rows affected.
Returning data to local variable result
You can get the SQl result to Python variable result as shown at the end of line #1 in the above listing. In the following cell, you can read that database cursor result as a Pandas data frame.
df = result.DataFrame()
df["dept_name"] = df["dept_name"].astype('string')
df["sum"] = df["sum"].astype("float")
df.set_index('dept_name', inplace=True)
However, before plotting the graph, you must convert the data frame columns to proper data types.
%matplotlib inline
import matplotlib.pyplot as plt
df[:-1].plot(kind="bar")
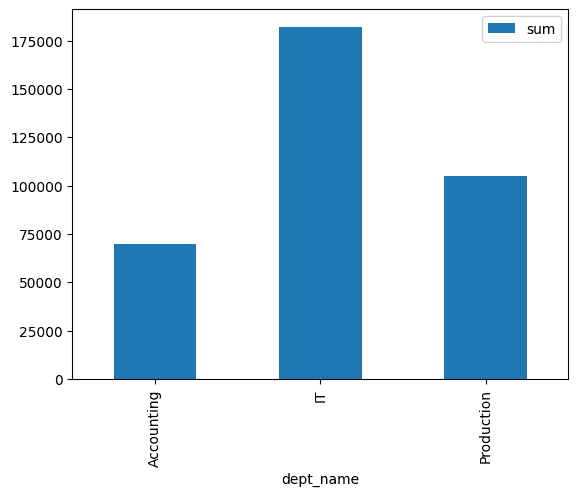
As an alternative, Cube provides all the possible aggregations as follows:
%%sql
select dept_name, sum(salary_amt)
from payroll
group by CUBE(dept_name)
order by dept_name
* postgresql+pg8000://postgres:***@postgres_db:5432/company
4 rows affected.
| dept_name | sum |
|---|---|
| Accounting | 70000.00 |
| IT | 182001.00 |
| Production | 105000.00 |
| None | 357001.00 |
If you want to calculate min, max, avg and the sum of salary_amt, you can execute the following SQL query:
SELECT dept_name
,MIN(salary_amt) AS min_dept_salary
,MAX(salary_amt) AS max_dept_salary
,AVG(salary_amt)::DECIMAL(8,2) AS avg_dept_salary
,SUM(salary_amt) AS total_dept_salary
FROM Payroll
GROUP BY dept_name
order by dept_name;
The above query calculates values on the entire data set3 and cannot link with a particular row. If you want to link the above values with a particular row, the solution is Windowing functions, where most analytics are needed.
Windows functions
Following the query, there are 18 employees in this organisation, and it shows the number of employees in each department with each and every row (employee identity).
%%sql
SELECT *
,COUNT(*) OVER() AS total_employee_count
,COUNT(*) OVER( PARTITION BY dept_name) AS dept_employee_count
,MIN(salary_amt) OVER (PARTITION BY dept_name) AS min_dept_salary
,MAX(salary_amt) OVER (PARTITION BY dept_name) AS max_dept_salary
,AVG(salary_amt) OVER (PARTITION BY dept_name)::DECIMAL(8,2) AS avg_dept_salary
,SUM(salary_amt) OVER (PARTITION BY dept_name) AS total_dept_salary
FROM Payroll order by dept_name, emp_name;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_no | emp_name | dept_name | salary_amt | total_employee_count | dept_employee_count | min_dept_salary | max_dept_salary | avg_dept_salary | total_dept_salary |
|---|---|---|---|---|---|---|---|---|---|
| 3 | Geetha Singh | Accounting | 13000.00 | 18 | 5 | 13000.00 | 16000.00 | 14000.00 | 70000.00 |
| 5 | Joseph Bastion | Accounting | 14000.00 | 18 | 5 | 13000.00 | 16000.00 | 14000.00 | 70000.00 |
| 2 | Maria Stone | Accounting | 13000.00 | 18 | 5 | 13000.00 | 16000.00 | 14000.00 | 70000.00 |
| 1 | Mark Stone | Accounting | 16000.00 | 18 | 5 | 13000.00 | 16000.00 | 14000.00 | 70000.00 |
| 4 | Richard Hathaway | Accounting | 14000.00 | 18 | 5 | 13000.00 | 16000.00 | 14000.00 | 70000.00 |
| 16 | James May | IT | 10000.00 | 18 | 7 | 10000.00 | 100000.00 | 26000.14 | 182001.00 |
| 14 | Jen Barber | IT | 28000.00 | 18 | 7 | 10000.00 | 100000.00 | 26000.14 | 182001.00 |
| 18 | Jeremy Clarkson | IT | 10000.00 | 18 | 7 | 10000.00 | 100000.00 | 26000.14 | 182001.00 |
| 17 | John Doe | IT | 100000.00 | 18 | 7 | 10000.00 | 100000.00 | 26000.14 | 182001.00 |
| 12 | Maurice Moss | IT | 12000.00 | 18 | 7 | 10000.00 | 100000.00 | 26000.14 | 182001.00 |
| 15 | Richard Hammond | IT | 10000.00 | 18 | 7 | 10000.00 | 100000.00 | 26000.14 | 182001.00 |
| 13 | Roy | IT | 12001.00 | 18 | 7 | 10000.00 | 100000.00 | 26000.14 | 182001.00 |
| 11 | Adam Scott | Production | 16000.00 | 18 | 6 | 12000.00 | 24000.00 | 17500.00 | 105000.00 |
| 7 | Adele Morse | Production | 13000.00 | 18 | 6 | 12000.00 | 24000.00 | 17500.00 | 105000.00 |
| 6 | Arthur Prince | Production | 12000.00 | 18 | 6 | 12000.00 | 24000.00 | 17500.00 | 105000.00 |
| 10 | Brian James | Production | 16000.00 | 18 | 6 | 12000.00 | 24000.00 | 17500.00 | 105000.00 |
| 8 | Sheamus O Kelly | Production | 24000.00 | 18 | 6 | 12000.00 | 24000.00 | 17500.00 | 105000.00 |
| 9 | Sheilah Flask | Production | 24000.00 | 18 | 6 | 12000.00 | 24000.00 | 17500.00 | 105000.00 |
The function ROW_NUMBER() in the following query provides the organisation's 1 to 18 lowest to largest salary, as shown in line #3. In line #4, the row number is assigned after the frame is split into partitions based on dept_name.
%%sql
SELECT
ROW_NUMBER() OVER(ORDER BY salary_amt) AS sal_row_no
, ROW_NUMBER() OVER (PARTITION BY dept_name ORDER BY salary_amt) AS dept_sal_row_no
,*
FROM Payroll order by dept_name
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| sal_row_no | dept_sal_row_no | emp_no | emp_name | dept_name | salary_amt |
|---|---|---|---|---|---|
| 7 | 1 | 3 | Geetha Singh | Accounting | 13000.00 |
| 9 | 2 | 2 | Maria Stone | Accounting | 13000.00 |
| 10 | 3 | 4 | Richard Hathaway | Accounting | 14000.00 |
| 11 | 4 | 5 | Joseph Bastion | Accounting | 14000.00 |
| 12 | 5 | 1 | Mark Stone | Accounting | 16000.00 |
| 1 | 1 | 18 | Jeremy Clarkson | IT | 10000.00 |
| 2 | 2 | 16 | James May | IT | 10000.00 |
| 3 | 3 | 15 | Richard Hammond | IT | 10000.00 |
| 4 | 4 | 12 | Maurice Moss | IT | 12000.00 |
| 6 | 5 | 13 | Roy | IT | 12001.00 |
| 17 | 6 | 14 | Jen Barber | IT | 28000.00 |
| 18 | 7 | 17 | John Doe | IT | 100000.00 |
| 5 | 1 | 6 | Arthur Prince | Production | 12000.00 |
| 8 | 2 | 7 | Adele Morse | Production | 13000.00 |
| 14 | 3 | 11 | Adam Scott | Production | 16000.00 |
| 13 | 4 | 10 | Brian James | Production | 16000.00 |
| 15 | 5 | 9 | Sheilah Flask | Production | 24000.00 |
| 16 | 6 | 8 | Sheamus O Kelly | Production | 24000.00 |
The following query shows where you can use SQL CTE. Row number 1 is always the highest earner.
%%sql
-- Find the highest earner of each department
WITH cteEarners AS (
SELECT *,
dept_name, salary_amt,
dense_rank() OVER w as earners
FROM Payroll
WINDOW w AS(PARTITION BY dept_name ORDER BY salary_amt DESC)
order by dept_name
) SELECT * FROM cteEarners where earners <= 2
* postgresql+pg8000://postgres:***@postgres_db:5432/company
9 rows affected.
| emp_no | emp_name | dept_name | salary_amt | dept_name_1 | salary_amt_1 | earners |
|---|---|---|---|---|---|---|
| 1 | Mark Stone | Accounting | 16000.00 | Accounting | 16000.00 | 1 |
| 4 | Richard Hathaway | Accounting | 14000.00 | Accounting | 14000.00 | 2 |
| 5 | Joseph Bastion | Accounting | 14000.00 | Accounting | 14000.00 | 2 |
| 17 | John Doe | IT | 100000.00 | IT | 100000.00 | 1 |
| 14 | Jen Barber | IT | 28000.00 | IT | 28000.00 | 2 |
| 9 | Sheilah Flask | Production | 24000.00 | Production | 24000.00 | 1 |
| 8 | Sheamus O Kelly | Production | 24000.00 | Production | 24000.00 | 1 |
| 11 | Adam Scott | Production | 16000.00 | Production | 16000.00 | 2 |
| 10 | Brian James | Production | 16000.00 | Production | 16000.00 | 2 |
LAG and LEAD are other functions to explore. For example:
%%sql
SELECT emp_no
, dept_name
, emp_name
, LAG(emp_name) OVER w AS previous_emp
, LEAD(emp_name) OVER w AS next_emp
From public.payroll
WINDOW w AS (PARTITION BY dept_name ORDER BY emp_no)
order by emp_no
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_no | dept_name | emp_name | previous_emp | next_emp |
|---|---|---|---|---|
| 1 | Accounting | Mark Stone | None | Maria Stone |
| 2 | Accounting | Maria Stone | Mark Stone | Geetha Singh |
| 3 | Accounting | Geetha Singh | Maria Stone | Richard Hathaway |
| 4 | Accounting | Richard Hathaway | Geetha Singh | Joseph Bastion |
| 5 | Accounting | Joseph Bastion | Richard Hathaway | None |
| 6 | Production | Arthur Prince | None | Adele Morse |
| 7 | Production | Adele Morse | Arthur Prince | Sheamus O Kelly |
| 8 | Production | Sheamus O Kelly | Adele Morse | Sheilah Flask |
| 9 | Production | Sheilah Flask | Sheamus O Kelly | Brian James |
| 10 | Production | Brian James | Sheilah Flask | Adam Scott |
| 11 | Production | Adam Scott | Brian James | None |
| 12 | IT | Maurice Moss | None | Roy |
| 13 | IT | Roy | Maurice Moss | Jen Barber |
| 14 | IT | Jen Barber | Roy | Richard Hammond |
| 15 | IT | Richard Hammond | Jen Barber | James May |
| 16 | IT | James May | Richard Hammond | John Doe |
| 17 | IT | John Doe | James May | Jeremy Clarkson |
| 18 | IT | Jeremy Clarkson | John Doe | None |
The following query creates from the lowest and highest earners for each department.
%%sql
-- Lowest and highest salary earners
WITH lowestSalaryCTE AS (
SELECT emp_no
, dept_name
, emp_name
, salary_amt
, ROW_NUMBER() OVER w AS r
From public.payroll
WINDOW w AS (PARTITION BY dept_name ORDER BY salary_amt ASC)
order by dept_name
),
highestSalaryCTE AS (
SELECT emp_no
, dept_name
, emp_name
, salary_amt
, ROW_NUMBER() OVER w AS r
From public.payroll
WINDOW w AS (PARTITION BY dept_name ORDER BY salary_amt DESC)
order by dept_name
) SELECT h.dept_name
, h.emp_name AS "Highest Salary Earner"
, h.salary_amt AS "Highest Salary"
, l.emp_name AS "Lowest Salary Earner"
, l.salary_amt as "Lowest Salary"
, (h.salary_amt - l.salary_amt) AS "Salary difference"
FROM highestSalaryCTE h JOIN lowestSalaryCTE l ON h.dept_name = l.dept_name
WHERE h.r = 1 and l.r =1
* postgresql+pg8000://postgres:***@postgres_db:5432/company
3 rows affected.
| dept_name | Highest Salary Earner | Highest Salary | Lowest Salary Earner | Lowest Salary | Salary difference |
|---|---|---|---|---|---|
| Accounting | Mark Stone | 16000.00 | Maria Stone | 13000.00 | 3000.00 |
| IT | John Doe | 100000.00 | James May | 10000.00 | 90000.00 |
| Production | Sheilah Flask | 24000.00 | Arthur Prince | 12000.00 | 12000.00 |
RANGE and ROWS
The row considers the current row as follows:
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (ROWS BETWEEN UNBOUNDED PRECEDING and CURRENT ROW)
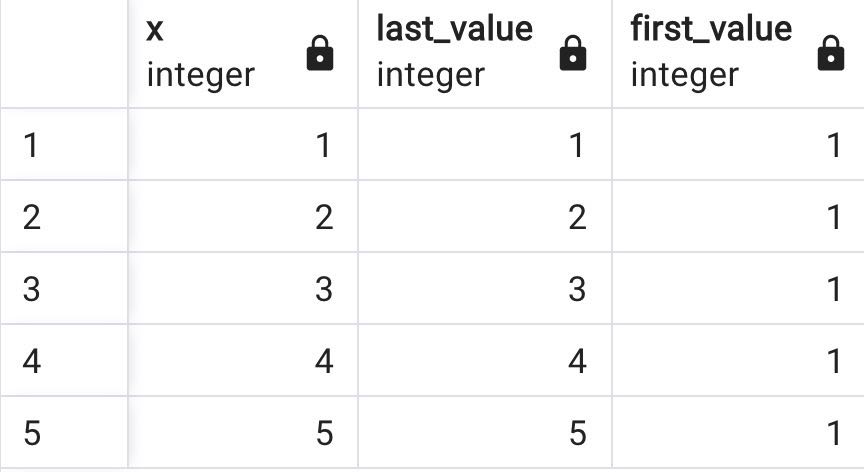
As shown in the above screenshot, the ROWS scope is growing gradually when the CURRENT ROW pointer is moving down in the Windows frame. Therefore, when the pointer moves to the next row within the partition, it changes its last value to the current row value (ascending order). However, the first value is found in the first row and continues that down the rows.
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
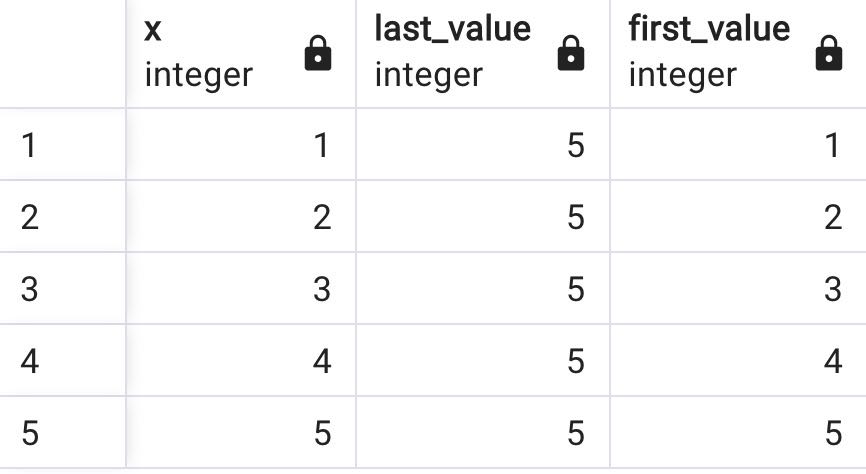
The screenshot above shows that the first value is constant of the last row while the ROW pointer moves upward. The first value is always the current row value, but the last value is always the last row value.
For example, in the following query, the total sum will be available in the first row.
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
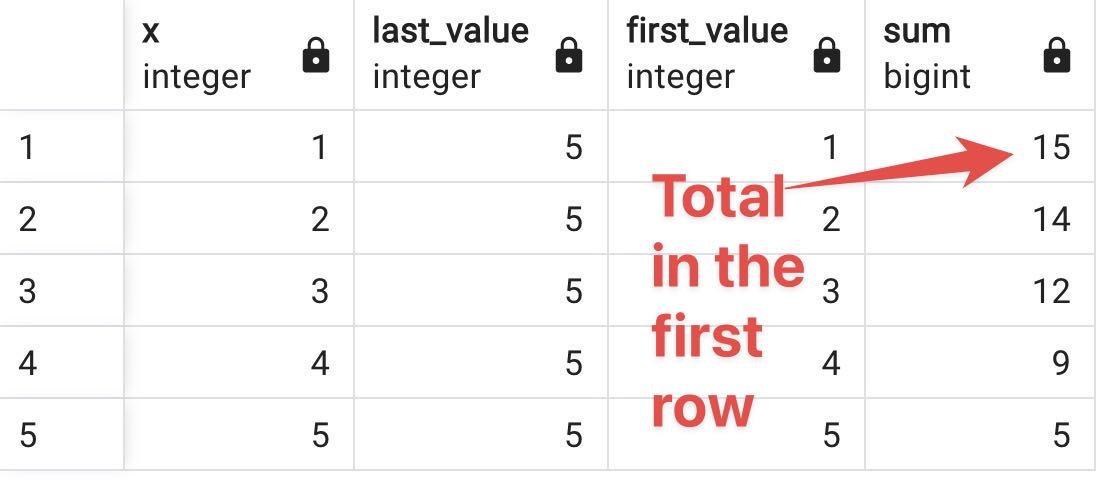
NOTE ❌: Frame start cannot be
UNBOUNDED FOLLOWINGsuch asROWS BETWEEN UNBOUNDED FOLLOWING AND CURRENT ROWas well, as frame end cannot beUNBOUNDED PRECEDINGsuch asROWS BETWEEN CURRENT ROW AND UNBOUNDED PRECEDING.
Here is the meaning of CURRENT ROW:
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (ROWS BETWEEN CURRENT ROW and CURRENT ROW);
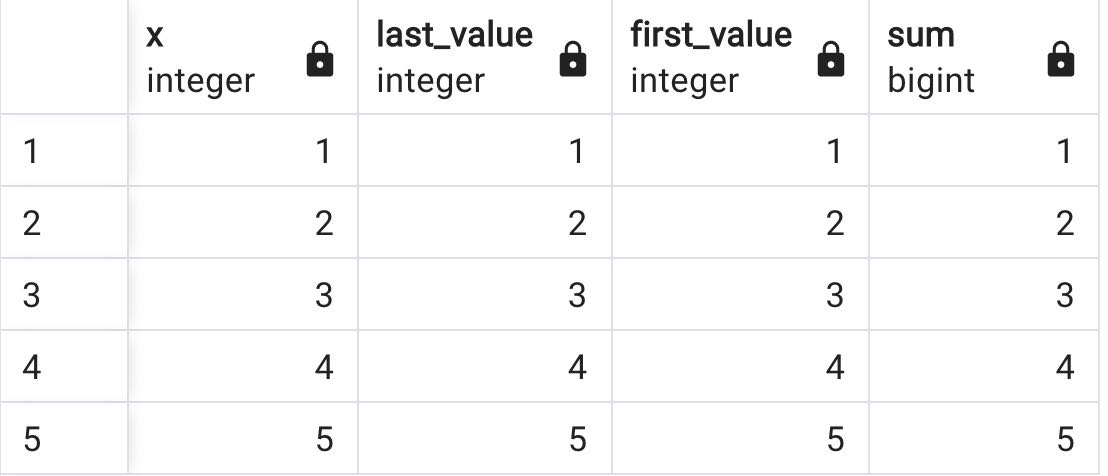
In the above query, the ROWS scope is limited to one row (last == first). Notice the first query of the following 3 SQL queries.
But, when it comes to the RANGE:
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (RANGE BETWEEN CURRENT ROW and CURRENT ROW);
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (RANGE BETWEEN UNBOUNDED PRECEDING and CURRENT ROW)
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
Above queries generate the same output:
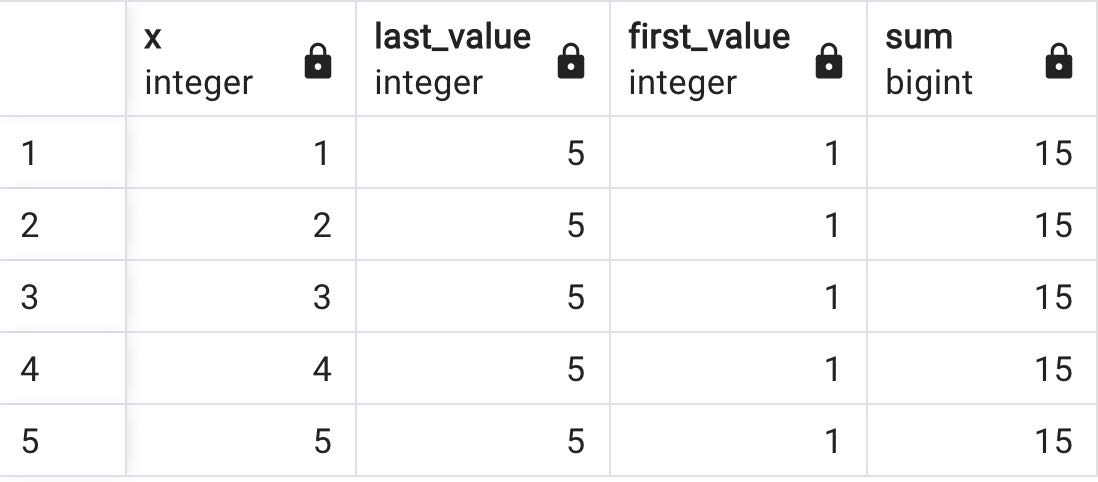
It is considered a complete partition, and the current row is considered an entire range.
If you select n PRCEDING as follows where n =1:
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_series(1,5) as f(x)
WINDOW w AS (ROWS BETWEEN 1 PRECEDING AND CURRENT ROW);
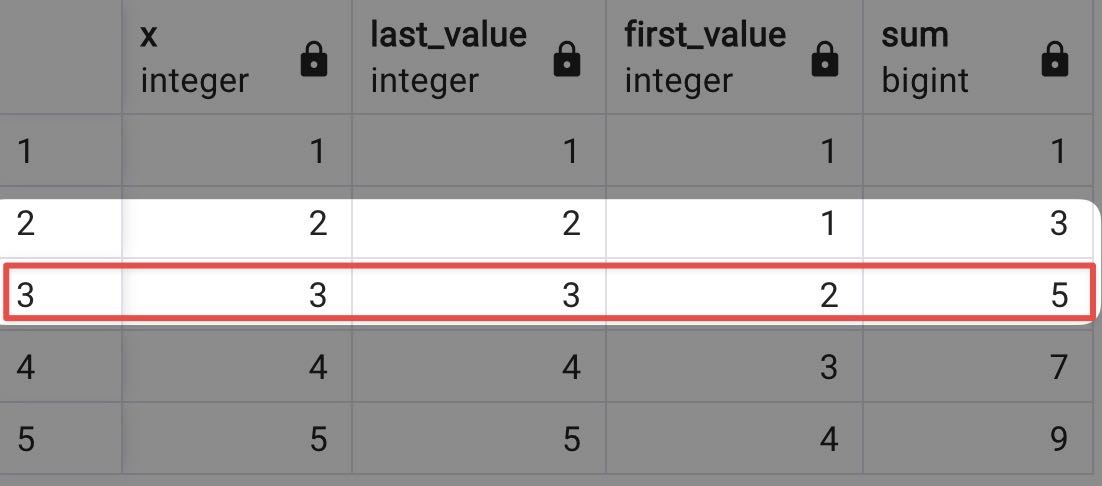
It calculates the sum only for the current and preceding rows. From the first and last values, you can find the scope boundary.
For example,
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_series(1,10) as f(x)
WINDOW w AS (ROWS BETWEEN 3 PRECEDING AND CURRENT ROW);
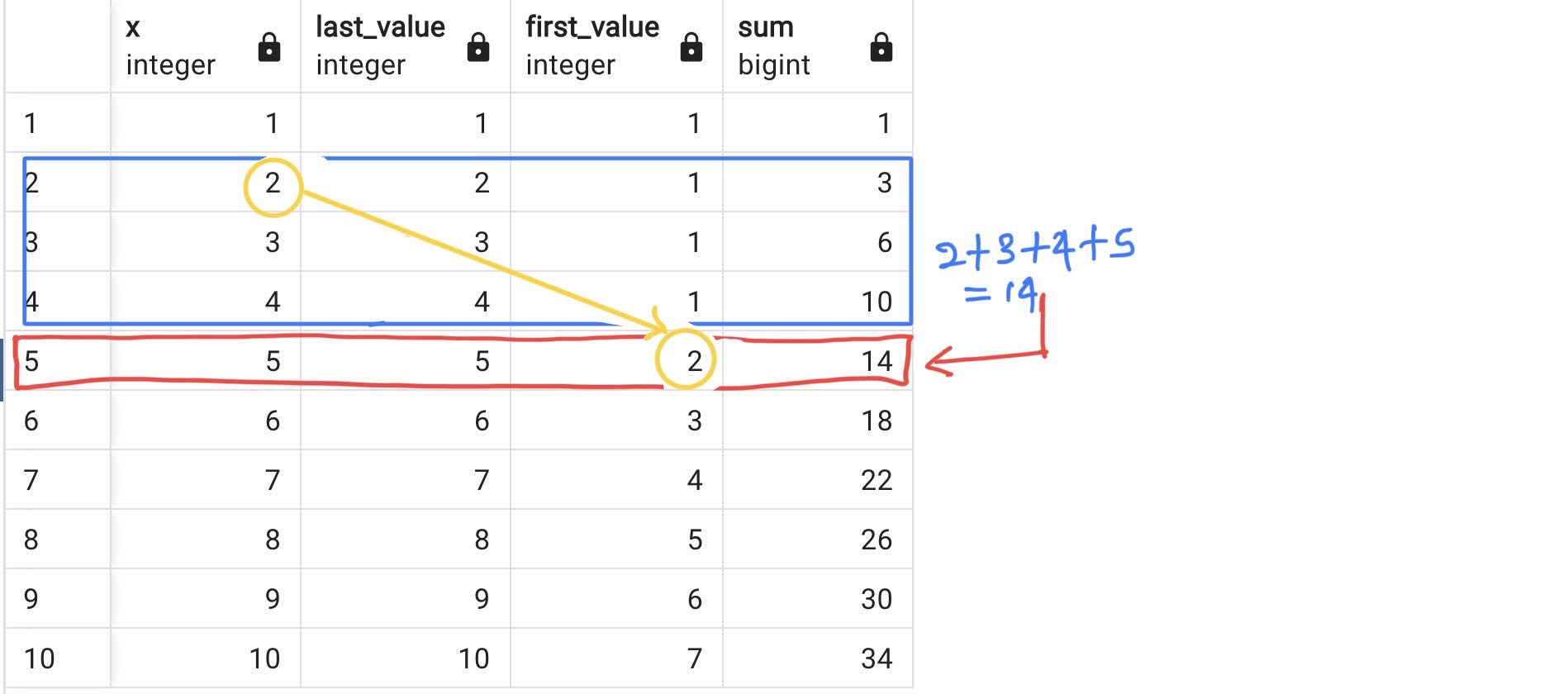
Generate the table using the following SQL (from The Magic of Window Functions in Postgres):
CREATE TABLE generate_1_to_5_x2 AS
SELECT ceil (x/2.0) AS x
FROM generate_series (1, 10) AS f(x);
In the following SQL, the CURRENT ROW represent tow rows as shown in the figure:
select x, LAST_VALUE(x) over w, FIRST_VALUE(x) over w, sum(x) over w
from generate_1_to_5_x2
WINDOW w AS (ORDER BY x);
In the above SQL query, ORDER BY x RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW was shortened because this is the default.

Functions
Functions are summarised in the following table4:
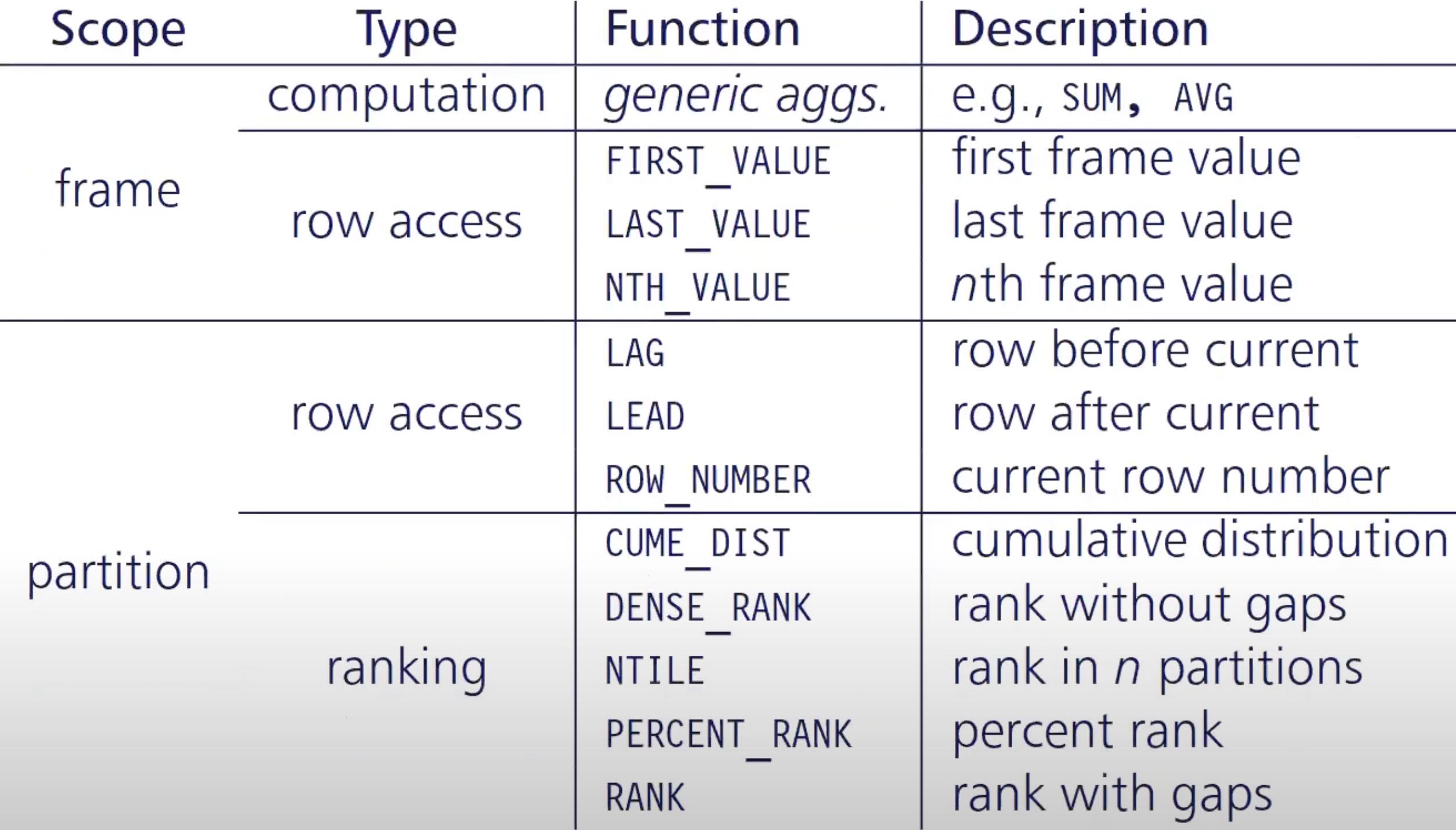
In the following query, each and every row is associated with its' lowest and highest earners.
%%sql
-- To get the names of the lowest and highest owners
SELECT emp_no
, dept_name
, emp_name
, salary_amt
, LAST_VALUE(emp_name) OVER (PARTITION BY dept_name ORDER BY salary_amt ASC
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS "Highest earner"
, LAST_VALUE(emp_name) OVER (PARTITION BY dept_name ORDER BY salary_amt DESC
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS "Lowest earner"
From public.payroll
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_no | dept_name | emp_name | salary_amt | Highest earner | Lowest earner |
|---|---|---|---|---|---|
| 2 | Accounting | Maria Stone | 13000.00 | Mark Stone | Geetha Singh |
| 3 | Accounting | Geetha Singh | 13000.00 | Mark Stone | Geetha Singh |
| 4 | Accounting | Richard Hathaway | 14000.00 | Mark Stone | Geetha Singh |
| 5 | Accounting | Joseph Bastion | 14000.00 | Mark Stone | Geetha Singh |
| 1 | Accounting | Mark Stone | 16000.00 | Mark Stone | Geetha Singh |
| 16 | IT | James May | 10000.00 | John Doe | Jeremy Clarkson |
| 15 | IT | Richard Hammond | 10000.00 | John Doe | Jeremy Clarkson |
| 18 | IT | Jeremy Clarkson | 10000.00 | John Doe | Jeremy Clarkson |
| 12 | IT | Maurice Moss | 12000.00 | John Doe | Jeremy Clarkson |
| 13 | IT | Roy | 12001.00 | John Doe | Jeremy Clarkson |
| 14 | IT | Jen Barber | 28000.00 | John Doe | Jeremy Clarkson |
| 17 | IT | John Doe | 100000.00 | John Doe | Jeremy Clarkson |
| 6 | Production | Arthur Prince | 12000.00 | Sheilah Flask | Arthur Prince |
| 7 | Production | Adele Morse | 13000.00 | Sheilah Flask | Arthur Prince |
| 11 | Production | Adam Scott | 16000.00 | Sheilah Flask | Arthur Prince |
| 10 | Production | Brian James | 16000.00 | Sheilah Flask | Arthur Prince |
| 8 | Production | Sheamus O Kelly | 24000.00 | Sheilah Flask | Arthur Prince |
| 9 | Production | Sheilah Flask | 24000.00 | Sheilah Flask | Arthur Prince |
The functions FIRST_VALUE and LAST_VALUE can be used as follows:
%%sql
-- To get the names of the lowest and highest owners
SELECT emp_no
, dept_name
, emp_name
, salary_amt
, FIRST_VALUE(emp_name) OVER (PARTITION BY dept_name ORDER BY salary_amt DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS "Highest earner"
, LAST_VALUE(emp_name) OVER (PARTITION BY dept_name ORDER BY salary_amt DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS "Lowest earner"
From public.payroll
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_no | dept_name | emp_name | salary_amt | Highest earner | Lowest earner |
|---|---|---|---|---|---|
| 1 | Accounting | Mark Stone | 16000.00 | Mark Stone | Geetha Singh |
| 4 | Accounting | Richard Hathaway | 14000.00 | Mark Stone | Geetha Singh |
| 5 | Accounting | Joseph Bastion | 14000.00 | Mark Stone | Geetha Singh |
| 2 | Accounting | Maria Stone | 13000.00 | Mark Stone | Geetha Singh |
| 3 | Accounting | Geetha Singh | 13000.00 | Mark Stone | Geetha Singh |
| 17 | IT | John Doe | 100000.00 | John Doe | Jeremy Clarkson |
| 14 | IT | Jen Barber | 28000.00 | John Doe | Jeremy Clarkson |
| 13 | IT | Roy | 12001.00 | John Doe | Jeremy Clarkson |
| 12 | IT | Maurice Moss | 12000.00 | John Doe | Jeremy Clarkson |
| 16 | IT | James May | 10000.00 | John Doe | Jeremy Clarkson |
| 15 | IT | Richard Hammond | 10000.00 | John Doe | Jeremy Clarkson |
| 18 | IT | Jeremy Clarkson | 10000.00 | John Doe | Jeremy Clarkson |
| 9 | Production | Sheilah Flask | 24000.00 | Sheilah Flask | Arthur Prince |
| 8 | Production | Sheamus O Kelly | 24000.00 | Sheilah Flask | Arthur Prince |
| 11 | Production | Adam Scott | 16000.00 | Sheilah Flask | Arthur Prince |
| 10 | Production | Brian James | 16000.00 | Sheilah Flask | Arthur Prince |
| 7 | Production | Adele Morse | 13000.00 | Sheilah Flask | Arthur Prince |
| 6 | Production | Arthur Prince | 12000.00 | Sheilah Flask | Arthur Prince |
Calculate the individual's salary as a percentage of the entire organisation's salary.
%%sql
SELECT emp_name, salary_amt
, round((salary_amt / SUM(salary_amt) OVER ()) * 100, 2) as pct
FROM payroll
ORDER BY salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | salary_amt | pct |
|---|---|---|
| John Doe | 100000.00 | 28.01 |
| Jen Barber | 28000.00 | 7.84 |
| Sheamus O Kelly | 24000.00 | 6.72 |
| Sheilah Flask | 24000.00 | 6.72 |
| Brian James | 16000.00 | 4.48 |
| Mark Stone | 16000.00 | 4.48 |
| Adam Scott | 16000.00 | 4.48 |
| Joseph Bastion | 14000.00 | 3.92 |
| Richard Hathaway | 14000.00 | 3.92 |
| Adele Morse | 13000.00 | 3.64 |
| Maria Stone | 13000.00 | 3.64 |
| Geetha Singh | 13000.00 | 3.64 |
| Roy | 12001.00 | 3.36 |
| Arthur Prince | 12000.00 | 3.36 |
| Maurice Moss | 12000.00 | 3.36 |
| Jeremy Clarkson | 10000.00 | 2.80 |
| Richard Hammond | 10000.00 | 2.80 |
| James May | 10000.00 | 2.80 |
Find who has salaries above or below the company's average salary.
%%sql
SELECT emp_name, salary_amt
, round (AVG(salary_amt) OVER (), 2) AS avg
, round(salary_amt - AVG(salary_amt) OVER (), 2) as diff
FROM payroll
ORDER BY salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | salary_amt | avg | diff |
|---|---|---|---|
| John Doe | 100000.00 | 19833.39 | 80166.61 |
| Jen Barber | 28000.00 | 19833.39 | 8166.61 |
| Sheamus O Kelly | 24000.00 | 19833.39 | 4166.61 |
| Sheilah Flask | 24000.00 | 19833.39 | 4166.61 |
| Brian James | 16000.00 | 19833.39 | -3833.39 |
| Mark Stone | 16000.00 | 19833.39 | -3833.39 |
| Adam Scott | 16000.00 | 19833.39 | -3833.39 |
| Joseph Bastion | 14000.00 | 19833.39 | -5833.39 |
| Richard Hathaway | 14000.00 | 19833.39 | -5833.39 |
| Adele Morse | 13000.00 | 19833.39 | -6833.39 |
| Maria Stone | 13000.00 | 19833.39 | -6833.39 |
| Geetha Singh | 13000.00 | 19833.39 | -6833.39 |
| Roy | 12001.00 | 19833.39 | -7832.39 |
| Arthur Prince | 12000.00 | 19833.39 | -7833.39 |
| Maurice Moss | 12000.00 | 19833.39 | -7833.39 |
| Jeremy Clarkson | 10000.00 | 19833.39 | -9833.39 |
| Richard Hammond | 10000.00 | 19833.39 | -9833.39 |
| James May | 10000.00 | 19833.39 | -9833.39 |
How much the employee makes than the next higher earner.
%%sql
SELECT emp_name, salary_amt
, salary_amt - LEAD(salary_amt,1) OVER (ORDER BY salary_amt DESC) AS diff
FROM payroll
ORDER BY salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | salary_amt | diff |
|---|---|---|
| John Doe | 100000.00 | 72000.00 |
| Jen Barber | 28000.00 | 4000.00 |
| Sheamus O Kelly | 24000.00 | 0.00 |
| Sheilah Flask | 24000.00 | 8000.00 |
| Brian James | 16000.00 | 0.00 |
| Mark Stone | 16000.00 | 0.00 |
| Adam Scott | 16000.00 | 2000.00 |
| Joseph Bastion | 14000.00 | 0.00 |
| Richard Hathaway | 14000.00 | 1000.00 |
| Adele Morse | 13000.00 | 0.00 |
| Maria Stone | 13000.00 | 0.00 |
| Geetha Singh | 13000.00 | 999.00 |
| Roy | 12001.00 | 1.00 |
| Arthur Prince | 12000.00 | 0.00 |
| Maurice Moss | 12000.00 | 2000.00 |
| Jeremy Clarkson | 10000.00 | 0.00 |
| Richard Hammond | 10000.00 | 0.00 |
| James May | 10000.00 | None |
How much do they earn more than the lowest-paid employee?
%%sql
SELECT emp_name, salary_amt
, salary_amt - LAST_VALUE(salary_amt) OVER w AS more
, round((salary_amt - LAST_VALUE(salary_amt) OVER w) / LAST_VALUE(salary_amt) OVER w * 100) AS pct_more
FROM payroll
WINDOW w AS (ORDER BY salary_amt DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
ORDER BY salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | salary_amt | more | pct_more |
|---|---|---|---|
| John Doe | 100000.00 | 90000.00 | 900 |
| Jen Barber | 28000.00 | 18000.00 | 180 |
| Sheamus O Kelly | 24000.00 | 14000.00 | 140 |
| Sheilah Flask | 24000.00 | 14000.00 | 140 |
| Brian James | 16000.00 | 6000.00 | 60 |
| Mark Stone | 16000.00 | 6000.00 | 60 |
| Adam Scott | 16000.00 | 6000.00 | 60 |
| Joseph Bastion | 14000.00 | 4000.00 | 40 |
| Richard Hathaway | 14000.00 | 4000.00 | 40 |
| Adele Morse | 13000.00 | 3000.00 | 30 |
| Maria Stone | 13000.00 | 3000.00 | 30 |
| Geetha Singh | 13000.00 | 3000.00 | 30 |
| Roy | 12001.00 | 2001.00 | 20 |
| Arthur Prince | 12000.00 | 2000.00 | 20 |
| Maurice Moss | 12000.00 | 2000.00 | 20 |
| Jeremy Clarkson | 10000.00 | 0.00 | 0 |
| Richard Hammond | 10000.00 | 0.00 | 0 |
| James May | 10000.00 | 0.00 | 0 |
Rank the employees on salary for the entire organisation.
%%sql
SELECT emp_name, salary_amt, RANK() OVER s, DENSE_RANK() OVER s
FROM payroll
WINDOW s AS (ORDER BY salary_amt DESC)
ORDER BY salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | salary_amt | rank | dense_rank |
|---|---|---|---|
| John Doe | 100000.00 | 1 | 1 |
| Jen Barber | 28000.00 | 2 | 2 |
| Sheamus O Kelly | 24000.00 | 3 | 3 |
| Sheilah Flask | 24000.00 | 3 | 3 |
| Brian James | 16000.00 | 5 | 4 |
| Mark Stone | 16000.00 | 5 | 4 |
| Adam Scott | 16000.00 | 5 | 4 |
| Joseph Bastion | 14000.00 | 8 | 5 |
| Richard Hathaway | 14000.00 | 8 | 5 |
| Adele Morse | 13000.00 | 10 | 6 |
| Maria Stone | 13000.00 | 10 | 6 |
| Geetha Singh | 13000.00 | 10 | 6 |
| Roy | 12001.00 | 13 | 7 |
| Arthur Prince | 12000.00 | 14 | 8 |
| Maurice Moss | 12000.00 | 14 | 8 |
| Jeremy Clarkson | 10000.00 | 16 | 9 |
| Richard Hammond | 10000.00 | 16 | 9 |
| James May | 10000.00 | 16 | 9 |
Difference employer earned against his/her departmental average. For that need to partition by department
%%sql
SELECT emp_name, dept_name, salary_amt
, round( AVG(salary_amt) OVER s, 2) AS avg
, round( salary_amt - AVG(salary_amt) OVER s,2) AS diff_from_avg
FROM payroll
WINDOW s AS (PARTITION BY dept_name)
ORDER BY dept_name, salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | dept_name | salary_amt | avg | diff_from_avg |
|---|---|---|---|---|
| Mark Stone | Accounting | 16000.00 | 14000.00 | 2000.00 |
| Joseph Bastion | Accounting | 14000.00 | 14000.00 | 0.00 |
| Richard Hathaway | Accounting | 14000.00 | 14000.00 | 0.00 |
| Maria Stone | Accounting | 13000.00 | 14000.00 | -1000.00 |
| Geetha Singh | Accounting | 13000.00 | 14000.00 | -1000.00 |
| John Doe | IT | 100000.00 | 26000.14 | 73999.86 |
| Jen Barber | IT | 28000.00 | 26000.14 | 1999.86 |
| Roy | IT | 12001.00 | 26000.14 | -13999.14 |
| Maurice Moss | IT | 12000.00 | 26000.14 | -14000.14 |
| Richard Hammond | IT | 10000.00 | 26000.14 | -16000.14 |
| James May | IT | 10000.00 | 26000.14 | -16000.14 |
| Jeremy Clarkson | IT | 10000.00 | 26000.14 | -16000.14 |
| Sheamus O Kelly | Production | 24000.00 | 17500.00 | 6500.00 |
| Sheilah Flask | Production | 24000.00 | 17500.00 | 6500.00 |
| Brian James | Production | 16000.00 | 17500.00 | -1500.00 |
| Adam Scott | Production | 16000.00 | 17500.00 | -1500.00 |
| Adele Morse | Production | 13000.00 | 17500.00 | -4500.00 |
| Arthur Prince | Production | 12000.00 | 17500.00 | -5500.00 |
Compared to the next low-earners salary in the same department
%%sql
SELECT emp_name, dept_name, salary_amt
, salary_amt - LEAD(salary_amt, 1) OVER w AS difference_to_next_earner
FROM payroll
WINDOW w AS (PARTITION BY dept_name ORDER BY salary_amt DESC)
ORDER BY dept_name, salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | dept_name | salary_amt | difference_to_next_earner |
|---|---|---|---|
| Mark Stone | Accounting | 16000.00 | 2000.00 |
| Richard Hathaway | Accounting | 14000.00 | 0.00 |
| Joseph Bastion | Accounting | 14000.00 | 1000.00 |
| Maria Stone | Accounting | 13000.00 | 0.00 |
| Geetha Singh | Accounting | 13000.00 | None |
| John Doe | IT | 100000.00 | 72000.00 |
| Jen Barber | IT | 28000.00 | 15999.00 |
| Roy | IT | 12001.00 | 1.00 |
| Maurice Moss | IT | 12000.00 | 2000.00 |
| James May | IT | 10000.00 | 0.00 |
| Richard Hammond | IT | 10000.00 | 0.00 |
| Jeremy Clarkson | IT | 10000.00 | None |
| Sheilah Flask | Production | 24000.00 | 0.00 |
| Sheamus O Kelly | Production | 24000.00 | 8000.00 |
| Adam Scott | Production | 16000.00 | 0.00 |
| Brian James | Production | 16000.00 | 3000.00 |
| Adele Morse | Production | 13000.00 | 1000.00 |
| Arthur Prince | Production | 12000.00 | None |
Employees ranking in the department and organisation.
%%sql
SELECT emp_name, dept_name, salary_amt
, RANK() OVER (PARTITION BY dept_name ORDER BY salary_amt DESC) AS dept_rank
, RANK() OVER (ORDER BY salary_amt DESC) as org_rank
FROM payroll
ORDER BY dept_name, salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | dept_name | salary_amt | dept_rank | org_rank |
|---|---|---|---|---|
| Mark Stone | Accounting | 16000.00 | 1 | 5 |
| Richard Hathaway | Accounting | 14000.00 | 2 | 8 |
| Joseph Bastion | Accounting | 14000.00 | 2 | 8 |
| Maria Stone | Accounting | 13000.00 | 4 | 10 |
| Geetha Singh | Accounting | 13000.00 | 4 | 10 |
| John Doe | IT | 100000.00 | 1 | 1 |
| Jen Barber | IT | 28000.00 | 2 | 2 |
| Roy | IT | 12001.00 | 3 | 13 |
| Maurice Moss | IT | 12000.00 | 4 | 14 |
| James May | IT | 10000.00 | 5 | 16 |
| Jeremy Clarkson | IT | 10000.00 | 5 | 16 |
| Richard Hammond | IT | 10000.00 | 5 | 16 |
| Sheilah Flask | Production | 24000.00 | 1 | 3 |
| Sheamus O Kelly | Production | 24000.00 | 1 | 3 |
| Brian James | Production | 16000.00 | 3 | 5 |
| Adam Scott | Production | 16000.00 | 3 | 5 |
| Adele Morse | Production | 13000.00 | 5 | 10 |
| Arthur Prince | Production | 12000.00 | 6 | 14 |
Other important functions
You can use window functions in the CASE WHEN, which allows a query to map various values. For example, in the following query, when the user paid more than the company's average salary, that employee is categorised as well paid; otherwise under paid else good paid.
%%sql
SELECT emp_name, salary_amt,
CASE
WHEN round(salary_amt - AVG(salary_amt) OVER (), 2) > 0 THEN 'well paid'
WHEN round(salary_amt - AVG(salary_amt) OVER (), 2) < 0 THEN 'under paid'
ELSE 'good paid'
END AS company_salary_status
FROM payroll
ORDER BY salary_amt DESC;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_name | salary_amt | company_salary_status |
|---|---|---|
| John Doe | 100000.00 | well paid |
| Jen Barber | 28000.00 | well paid |
| Sheamus O Kelly | 24000.00 | well paid |
| Sheilah Flask | 24000.00 | well paid |
| Brian James | 16000.00 | under paid |
| Mark Stone | 16000.00 | under paid |
| Adam Scott | 16000.00 | under paid |
| Joseph Bastion | 14000.00 | under paid |
| Richard Hathaway | 14000.00 | under paid |
| Adele Morse | 13000.00 | under paid |
| Maria Stone | 13000.00 | under paid |
| Geetha Singh | 13000.00 | under paid |
| Roy | 12001.00 | under paid |
| Arthur Prince | 12000.00 | under paid |
| Maurice Moss | 12000.00 | under paid |
| Jeremy Clarkson | 10000.00 | under paid |
| Richard Hammond | 10000.00 | under paid |
| James May | 10000.00 | under paid |
One of the tedious problems in the data set is null values. You can use the COALESCE function to resolve the null problem.
%%sql
WITH cte AS (
SELECT emp_no
, dept_name
, emp_name
, LAG(emp_name) OVER w AS previous_emp
, LEAD(emp_name) OVER w AS next_emp
From public.payroll
WINDOW w AS (PARTITION BY dept_name ORDER BY emp_no)
order by emp_no
) SELECT emp_no, dept_name, emp_name,
COALESCE(previous_emp, 'No Previous'),
COALESCE(next_emp, 'No Next')
FROM cte
* postgresql+pg8000://postgres:***@postgres_db:5432/company
18 rows affected.
| emp_no | dept_name | emp_name | coalesce | coalesce_1 |
|---|---|---|---|---|
| 1 | Accounting | Mark Stone | No Previous | Maria Stone |
| 2 | Accounting | Maria Stone | Mark Stone | Geetha Singh |
| 3 | Accounting | Geetha Singh | Maria Stone | Richard Hathaway |
| 4 | Accounting | Richard Hathaway | Geetha Singh | Joseph Bastion |
| 5 | Accounting | Joseph Bastion | Richard Hathaway | No Next |
| 6 | Production | Arthur Prince | No Previous | Adele Morse |
| 7 | Production | Adele Morse | Arthur Prince | Sheamus O Kelly |
| 8 | Production | Sheamus O Kelly | Adele Morse | Sheilah Flask |
| 9 | Production | Sheilah Flask | Sheamus O Kelly | Brian James |
| 10 | Production | Brian James | Sheilah Flask | Adam Scott |
| 11 | Production | Adam Scott | Brian James | No Next |
| 12 | IT | Maurice Moss | No Previous | Roy |
| 13 | IT | Roy | Maurice Moss | Jen Barber |
| 14 | IT | Jen Barber | Roy | Richard Hammond |
| 15 | IT | Richard Hammond | Jen Barber | James May |
| 16 | IT | James May | Richard Hammond | John Doe |
| 17 | IT | John Doe | James May | Jeremy Clarkson |
| 18 | IT | Jeremy Clarkson | John Doe | No Next |
How to create a table with random data
For my analytic data testing, I need sample data always. There are a few ways to bring the data to Postgres: either generate it using SQL or input from external sources.
Generate
Here is the example5 to generate the sales data:
-- Create a table with an index
CREATE TABLE sales(id integer GENERATED ALWAYS AS IDENTITY,
product varchar(100),
order_date date, quantity integer,
CONSTRAINT pk_sales PRIMARY KEY(id)
);
-- insert data
INSERT INTO sales(product, order_date, quantity)
WITH d AS( SELECT f.product, d.ts::date,
mod(date_part('epoch', d.ts)::integer, f.ord + 73) AS quantity
FROM unnest(ARRAY['pen', 'book']) WITH ORDINALITY AS f(product,ord)
CROSS JOIN generate_series('2021-11-01'::timestamp,
'2022-01-07'::timestamp, interval '1.2 hours') AS d(ts)
WHERE mod(date_part('epoch', d.ts)::integer,7) = 1
)
SELECT *
FROM d WHERE quantity > 0;
In the pgAdmin,
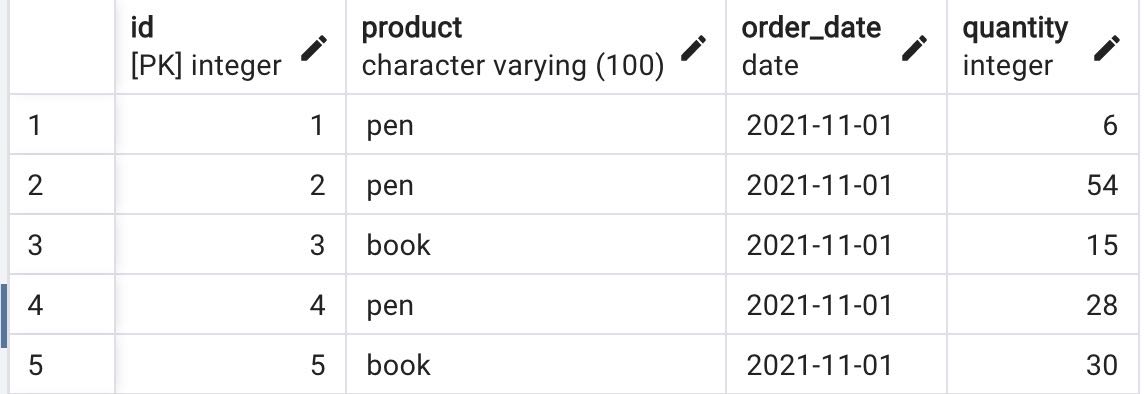
For example, you can calculate the running total of the number of sales as follows:
%%sql
SELECT to_char(order_date, 'YYYY-MM') AS month, product,
count(*) no_of_sales,
SUM(count(*)) OVER w AS no_of_sales_to_date,
SUM(quantity) As month_sales,
SUM(SUM(quantity)) OVER w AS sales_to_date
FROM sales
GROUP BY product, month
WINDOW w AS (PARTITION BY product ORDER BY to_char(order_date, 'YYYY-MM'))
ORDER BY product, month;
* postgresql+pg8000://postgres:***@postgres_db:5432/company
6 rows affected.
| month | product | no_of_sales | no_of_sales_to_date | month_sales | sales_to_date |
|---|---|---|---|---|---|
| 2021-11 | book | 68 | 68 | 2550 | 2550 |
| 2021-12 | book | 71 | 139 | 2640 | 5190 |
| 2022-01 | book | 13 | 152 | 510 | 5700 |
| 2021-11 | pen | 83 | 83 | 3076 | 3076 |
| 2021-12 | pen | 86 | 169 | 3134 | 6210 |
| 2022-01 | pen | 17 | 186 | 614 | 6824 |
In the above query, the shared WINDOW frame partitions are created on product, and order those partitions on monthly. cumulative sums are calculated on these partitions.
NOTE: The complete Windowing frame should be as follows
WINDOW w AS (PARTITION BY product ORDER BY to_char(order_date, 'YYYY-MM') RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)Default has been omitted in the above query.
Create pglia database using external SQLs
- clone the Git repo.
git clone git@github.com:devrimgunduz/pagila.git
- Access the PSQL prompt
docker exec -it postgres psql -U postgres
- Create DATABASE in the PSQL prompt
CREATE DATABASE pagila;
- exit
Create Schema
cat pagila/pagila-schema.sql | docker exec -i postgres psql -U postgres -d pagila
To insert data
cat pagila/pagila-data.sql | docker exec -i postgres psql -U postgres -d pagila
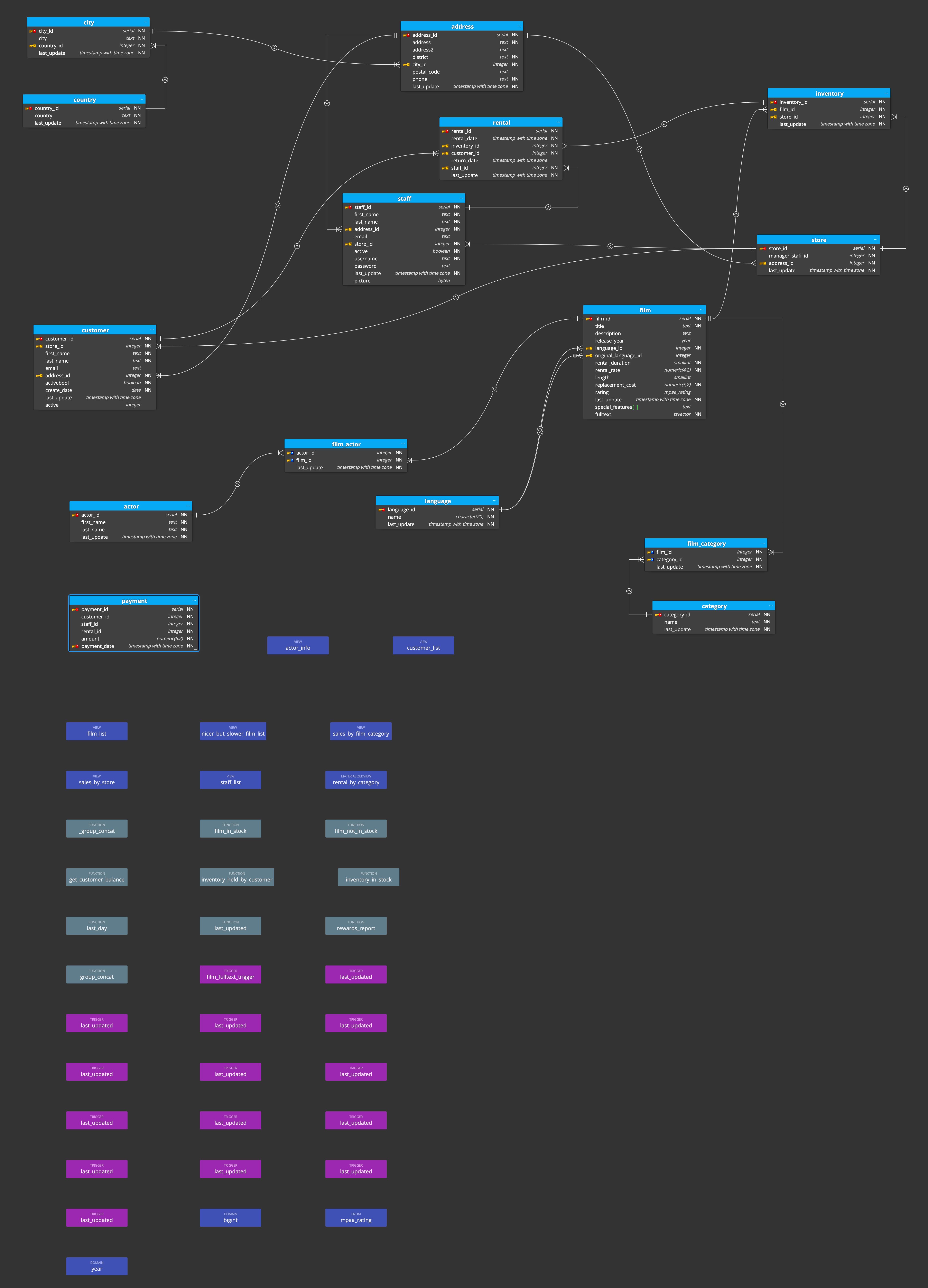
Connect to the database

- access the PSQL prompt
- connect to the pagila database
- list all the relations


Comments
Post a Comment
commented your blog