PySpark relational operations
In this blog I explore the PySpark DataFrame API to create SQL JOIN and Windowing functionality. I am using MovieLens1 dataset to explain. In addition to SQL JOIN and CASE, advanced topic such as SQL Window and Pivot will be discussed here.
In my last blog post2, I've explained how to use Hive metastore which is more intent to use SQL only. For the full list, see the Spark SQL documentation3.
First start the spark session as follows. I've changed the logging level as well.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Releational operations").getOrCreate()
sc = spark.sparkContext
# sel the log leve
sc.setLogLevel('ERROR')
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/02/21 19:42:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Read the movies as DataFrame from the /Users/ojitha/datasets/ml-25m/movies.csv CSV file.
Create Dataframes
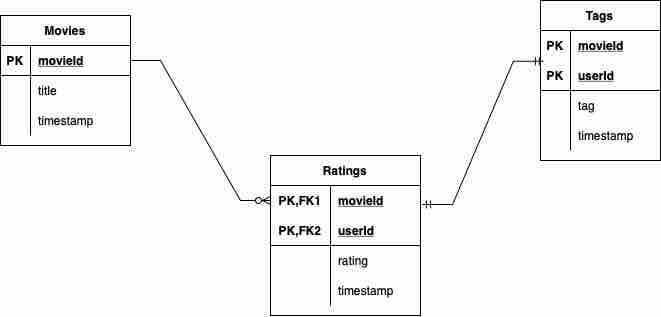
There are three CSV files to load as DataFrames: movie, rating and tag. Here the ER diagram:
First create a DataFrame from the movies file
movies_df = spark.read.format('csv') \
.option('header', True) \
.option('inferSchema',True) \
.load('/Users/ojitha/datasets/ml-25m/movies.csv').alias('movie')
movies_df.printSchema()
root
|-- movieId: integer (nullable = true)
|-- title: string (nullable = true)
|-- genres: string (nullable = true)
The movieId is the primary key of this file table (movie).
movies_df.show(5)
+-------+--------------------+--------------------+
|movieId| title| genres|
+-------+--------------------+--------------------+
| 1| Toy Story (1995)|Adventure|Animati...|
| 2| Jumanji (1995)|Adventure|Childre...|
| 3|Grumpier Old Men ...| Comedy|Romance|
| 4|Waiting to Exhale...|Comedy|Drama|Romance|
| 5|Father of the Bri...| Comedy|
+-------+--------------------+--------------------+
only showing the top 5 rows
Read ratings CSV file from the /Users/ojitha/datasets/ml-25m/ratings.csv. And name that table as rating. The primary key is composite of movieId+userId for the rating table.
ratings_df = spark.read.format('csv') \
.option('header', True) \
.option('inferSchema',True) \
.load('/Users/ojitha/datasets/ml-25m/ratings.csv').alias('rating')
ratings_df.printSchema()
[Stage 4:=========> (2 + 10) / 12]
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- rating: double (nullable = true)
|-- timestamp: integer (nullable = true)
JOIN
JOIN operation is one of the most common of SQl and in the moment of shuffle. Spark has five distinct joing strategies:
- the broadcast hash join(BHJ)
- shuffle hash join (SHJ)
- shuffle sort merge joing (SMJ)
- Broadcast nested loop join (BNLJ)
- Shuffle and replicated nested loop join (cartesian product join)
NOTE: BHJ and SHJ are the most common join strategies.
Use the DataFrame API to Join the movies_df and ratings_df DataFrames.
from pyspark.sql.functions import col
movie_ratings_df = ratings_df.join(
movies_df,['movieId']
)
movie_ratings_df.show(5)
+-------+------+------+----------+--------------------+--------------------+
|movieId|userId|rating| timestamp| title| genres|
+-------+------+------+----------+--------------------+--------------------+
| 296| 1| 5.0|1147880044| Pulp Fiction (1994)|Comedy|Crime|Dram...|
| 306| 1| 3.5|1147868817|Three Colors: Red...| Drama|
| 307| 1| 5.0|1147868828|Three Colors: Blu...| Drama|
| 665| 1| 5.0|1147878820| Underground (1995)| Comedy|Drama|War|
| 899| 1| 3.5|1147868510|Singin' in the Ra...|Comedy|Musical|Ro...|
+-------+------+------+----------+--------------------+--------------------+
only showing top 5 rows
If you execute movie_ratings_df.explain(), in the output, you can find the `` BroadcastHashJoin as shown in line# 4.
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [movieId#2836, userId#2835, rating#2837, timestamp#2838, title#2814, genres#2815]
+- BroadcastHashJoin [movieId#2836], [movieId#2813], Inner, BuildRight, false
:- Filter isnotnull(movieId#2836)
: +- FileScan csv [userId#2835,movieId#2836,rating#2837,timestamp#2838]
And in the DAG visualisation in the Spark Web UI4 as well.
Let's create tags DataFrame from the /Users/ojitha/datasets/ml-25m/tags.csv CSV file. The primary key is movieId+userId for the DataFrame tag.
tags_df = spark.read.format('csv') \
.option('header', True) \
.option('inferSchema',True) \
.load('/Users/ojitha/datasets/ml-25m/tags.csv').alias('tag')
tags_df.printSchema()
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- tag: string (nullable = true)
|-- timestamp: string (nullable = true)
We can join tags_df to the movie_ratings_df as follows.
movie_rating_tags_df = movie_ratings_df.join(
tags_df,['movieId','userId']
).select(
'movieId'
, 'userId'
, 'rating'
, col('rating.timestamp').alias('rating_ts')
, col('tag.timestamp').alias('tag_ts')
, 'title'
, 'genres'
, 'tag'
)
movie_rating_tags_df.show(5)
[Stage 14:> (0 + 1) / 1]
+-------+------+------+----------+----------+----------------+--------------------+-----------+
|movieId|userId|rating| rating_ts| tag_ts| title| genres| tag|
+-------+------+------+----------+----------+----------------+--------------------+-----------+
| 1| 40187| 3.5|1271465920|1271465930|Toy Story (1995)|Adventure|Animati...|buddy movie|
| 1| 40187| 3.5|1271465920|1271465933|Toy Story (1995)|Adventure|Animati...| Tom Hanks|
| 1| 40187| 3.5|1271465920|1271465935|Toy Story (1995)|Adventure|Animati...| witty|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)|Adventure|Animati...| cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)|Adventure|Animati...| funny|
+-------+------+------+----------+----------+----------------+--------------------+-----------+
only showing top 5 rows
UDF and explode function
In the movie_rating_tags_df (with 834731 records), genres are in pipe separated string which is a little bit complex for analysis tasks where we need tag based filtering:
- Convert pipe separated string to a list using a UDF
- After step 1 above, explode the rows on the list
Create a user-defined function(UDF) to convert pipe separated string such as Adventure|Children|Fantasy to a list.
from pyspark.sql.functions import udf
from pyspark.sql.types import ArrayType, StringType
@udf(returnType=ArrayType(StringType()))
def toList(source):
return source.split("|")
Explode the DataFrame movie_rating_tags_df and create a new DataFrame movie_rating_tags_exploded_df. When you want to repeatedly access the same large data set, better to cache.
from pyspark.sql.functions import explode
df = movie_rating_tags_df.select(
'movieId', 'userId', 'rating.rating', 'rating_ts', 'tag_ts', 'movie.title'
, explode(toList('genres')).alias('genre')
, 'tag'
).cache()
df.count()
2283268
As you see there are 2283268 records after explode. Now you are ready to query the cached dataset. When you call cache, the DataFrame will be cached and faster to get response. You can find the DAD in the SparkUI (http://
df.show(5)
+-------+------+------+----------+----------+----------------+---------+----+
|movieId|userId|rating| rating_ts| tag_ts| title| genre| tag|
+-------+------+------+----------+----------+----------------+---------+----+
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)|Adventure|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)|Animation|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)| Children|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)| Comedy|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)| Fantasy|cute|
+-------+------+------+----------+----------+----------------+---------+----+
only showing top 5 rows
If you wish to use SQL, first you have to create temporary view from the movie_rating_tags_exploded_df DataFrame.
df.createOrReplaceTempView('movies')
For example to show 5 records:
spark.sql('Select * FROM movies LIMIT 5;').show()
+-------+------+------+----------+----------+----------------+---------+----+
|movieId|userId|rating| rating_ts| tag_ts| title| genre| tag|
+-------+------+------+----------+----------+----------------+---------+----+
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)|Adventure|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)|Animation|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)| Children|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)| Comedy|cute|
| 1| 48627| 4.5|1337188285|1337209280|Toy Story (1995)| Fantasy|cute|
+-------+------+------+----------+----------+----------------+---------+----+
Windowing
Windowing is one of the best SQL mechanisms to calculate moving average or calculating a cumulative sum. Here a simple example to show the windowing of customers to find the highest rating to lowest. Window function calculates a return value for every input row of a table based on a group of rows, called the Frame5.
spark.sql("""
SELECT userId, rating, title, genre, tag
-- windowing
, row_number() OVER ( PARTITION BY userId ORDER BY rating DESC) as row
FROM movies WHERE genre='Drama' AND tag='Jane Austen';
""").show(10, truncate=False)
[Stage 35:=======================================> (149 + 12) / 200]
+------+------+----------------------------+-----+-----------+---+
|userId|rating|title |genre|tag |row|
+------+------+----------------------------+-----+-----------+---+
|2640 |4.5 |Sense and Sensibility (1995)|Drama|Jane Austen|1 |
|2640 |3.5 |Persuasion (1995) |Drama|Jane Austen|2 |
|3038 |4.0 |Pride & Prejudice (2005) |Drama|Jane Austen|1 |
|3627 |4.0 |Pride & Prejudice (2005) |Drama|Jane Austen|1 |
|3975 |4.0 |Pride & Prejudice (2005) |Drama|Jane Austen|1 |
|3975 |4.0 |Persuasion (1995) |Drama|Jane Austen|2 |
|3975 |4.0 |Pride and Prejudice (1995) |Drama|Jane Austen|3 |
|7377 |3.5 |Pride and Prejudice (1940) |Drama|Jane Austen|1 |
|7621 |5.0 |Pride & Prejudice (2005) |Drama|Jane Austen|1 |
|7621 |4.0 |Sense and Sensibility (1995)|Drama|Jane Austen|2 |
+------+------+----------------------------+-----+-----------+---+
only showing top 10 rows
You can write the same SQL using DataFrame API as follows.
NOTE: The filter should be before apply the windows as showing in line# 7.
from pyspark.sql.window import Window
import pyspark.sql.functions as func
# windowing specification
windowSpec = Window.partitionBy(df['userId']).orderBy(df['rating'].desc())
df.filter((df.genre == 'Drama') & (df.tag == 'Jane Austen')) \
.withColumn('row',func.row_number().over(windowSpec)) \
.select('userId', 'rating', 'title', 'genre', 'tag', 'row') \
.show(10)
[Stage 42:====================================================> (194 + 6) / 200]
+------+------+--------------------+-----+-----------+---+
|userId|rating| title|genre| tag|row|
+------+------+--------------------+-----+-----------+---+
| 2640| 4.5|Sense and Sensibi...|Drama|Jane Austen| 1|
| 2640| 3.5| Persuasion (1995)|Drama|Jane Austen| 2|
| 3038| 4.0|Pride & Prejudice...|Drama|Jane Austen| 1|
| 3627| 4.0|Pride & Prejudice...|Drama|Jane Austen| 1|
| 3975| 4.0|Pride & Prejudice...|Drama|Jane Austen| 1|
| 3975| 4.0| Persuasion (1995)|Drama|Jane Austen| 2|
| 3975| 4.0|Pride and Prejudi...|Drama|Jane Austen| 3|
| 7377| 3.5|Pride and Prejudi...|Drama|Jane Austen| 1|
| 7621| 5.0|Pride & Prejudice...|Drama|Jane Austen| 1|
| 7621| 4.0|Sense and Sensibi...|Drama|Jane Austen| 2|
+------+------+--------------------+-----+-----------+---+
only showing top 10 rows
CASE
You can add new column to the DataFrame or rename.
from pyspark.sql.functions import expr
movie_status = movie_ratings_df.withColumn(
"status", expr("""
CASE
WHEN rating < 4 THEN 'general'
WHEN rating > 4 AND rating <= 5 THEN 'good'
WHEN rating > 5 AND rating <= 7 THEN 'better'
WHEN rating > 7 THEN 'excellent'
ELSE 'watchable'
END
""")
)
Pivoting
This will allow rows to column and columns to rows transformation.
from pyspark.sql import Row
Eater = Row("id", "name", "fruit")
eater1 = Eater(1 , 'Henry' , 'strawberries')
eater2 = Eater(2 , 'Henry' , 'grapefruit')
eater3 = Eater(3 , 'Henry' , 'watermelon')
eater4 = Eater( 4 , 'Lily' , 'strawberries')
eater5 = Eater( 5 , 'Lily' , 'watermelon')
eater6 = Eater(6 , 'Lily' , 'strawberries')
eater7 = Eater(7 , 'Lily' , 'watermelon')
temp = spark.createDataFrame([eater1, eater2, eater3, eater4, eater5, eater6, eater7])
temp.createOrReplaceTempView('fruits')
temp.groupBy('name').pivot('fruit').count().show()
+-----+----------+------------+----------+
| name|grapefruit|strawberries|watermelon|
+-----+----------+------------+----------+
| Lily| null| 2| 2|
|Henry| 1| 1| 1|
+-----+----------+------------+----------+
Following is the direct exam got from the SQL Pocket Guide, 4th Edition.
pivot_tbl=spark.sql("""
-- Oracle
SELECT *
FROM fruits
PIVOT
(COUNT(id) FOR fruit IN ('strawberries',
'grapefruit', 'watermelon'));
""")
pivot_tbl.show()
+-----+------------+----------+----------+
| name|strawberries|grapefruit|watermelon|
+-----+------------+----------+----------+
| Lily| 2| null| 2|
|Henry| 1| 1| 1|
+-----+------------+----------+----------+
Stop the Spark session to end.
spark.stop()
references
-
recommended for new research, https://grouplens.org/datasets/movielens/ ↩
-
Spark SQL using Hive metastore, https://ojitha.blogspot.com/2022/02/spark-sql-using-hive-metastore.html ↩
-
Spark SQL Documentation, https://spark.apache.org/docs/latest/api/sql/index.html ↩
-
Introducing Window Functions in Spark SQL, https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html ↩


Comments
Post a Comment
commented your blog